
Project B11:
Semantic roles, case relations, and cross-clausal
reference in Tibetan
|
||
|
||
|
||
|
||
|
||
|
||
|
||
Statistical evaluation
Figures:Realisation of arguments
Distribution of arguments (the ten most frequent roles)
Sensitivity of roles for deletion or omission
Congruence patterns between antecedents and anaphoric elements
Reference relations for zero-anaphora (distance-sentitive)
The annotation revealed that, despite great differences in grammar and style and in the length of the annotation, all texts showed a similar behaviour with respect to argument realisation: more than 40% of all arguments remained non-realised, see Fig. 1.
The texts differ, however, in how many non-realised arguments have an explicit antecedent in the preceding text. This difference is pragmatically conditioned and genre-sensitive: The TVP has many doctrinal passages which do not refer to specific human actors and thus the corresponding arguments remain unspecified even without having an antecedent.
|
database |
OTC |
% |
TVP |
% |
LLV |
% |
|
expected arguments (real
complements) |
505 |
|
1795 |
|
1335 |
|
|
realised arguments |
269 |
53 |
999 |
56 |
758 |
57 |
|
empty arguments |
198 |
39 |
639 |
36 |
440 |
33 |
|
empty arguments with
antecedent |
156 |
(79) |
421 |
(66) |
333 |
(76) |
|
empty arguments without
antecedent |
42 |
(21) |
218 |
(34) |
107 |
(24) |
|
omitted arguments |
39 |
8 |
157 |
9 |
133 |
10 |
|
omitted arguments with
antecedent |
21 |
(54) |
27 |
(17) |
33 |
(25) |
|
demonstrative pronouns |
12 |
|
123 |
|
105 |
|
|
demonstrative pronouns with
antecedent |
8 |
(67) |
95 |
(77) |
98 |
(93) |
|
demonstrative pronouns
without antecedent |
4 |
(33) |
28 |
(23) |
7 |
(7) |
other figures
Distribution of arguments (the ten most frequent roles)
Sensitivity of roles for deletion or omission
Congruence patterns between antecedents and anaphoric elements
Reference relations for zero-anaphora (distance-sentitive)
top
Distribution
of arguments (the ten most frequent roles)
Fig. 2 shows the ten most common roles, with and without regard of valency. For all roles and abbreviations see our definition of arguments. Somewhat unexpected, the texts show quite a similar (in part even identical) distribution for the first five most frequent roles. Among the next frequent roles, one finds more variation, but still some similarities. The high frequency of location arguments is particularly noteworthy: if valency is disregarded, LCT constitutes the third-most frequent role in all three texts (OTC: 12,28%, TVP: 10,03%, LLV: 13,00%), after eA (20,20%, 18,94%, 22,84%) and P (13,27%, 12,70%, 15,56%). If valency is regarded, it is even the most frequent role (12,28%, 10,07%, 13%) before eA2 (8,32%, 9,81%, 10,07%) and P2 (TVP 8,97%) or R (OTC 7,92%, LLV 9,32%). This reflects the frequent occurrence of motion, position and existence verbs, while the high number of omissions (see Fig. 3) reflects the overall pertinence of locations throughout longer chains of events.
|
valency-sensitive |
|||||||||
|
|
OTC |
TVP |
LLV |
||||||
|
|
roles |
absolute |
% |
roles |
absolute |
% |
roles |
absolute |
% |
|
1 |
LCT |
62 |
12,28 |
LCT |
180 |
10,03 |
LCT |
173 |
13,00 |
|
2 |
eA2 |
42 |
8,32 |
eA2 |
176 |
9,81 |
eA2 |
134 |
10,07 |
|
3 |
R |
40 |
7,92 |
P2 |
161 |
8,97 |
R |
124 |
9,32 |
|
4 |
P2 |
35 |
6,93 |
R |
106 |
5,91 |
P2 |
94 |
7,06 |
|
5 |
CONTdir |
31 |
6,14 |
CONTdir |
103 |
5,74 |
eA2+ |
93 |
6,99 |
|
6 |
eA2+ |
27 |
5,35 |
eA2+ |
102 |
5,68 |
CONTdir |
77 |
5,79 |
|
7 |
eA3 |
26 |
5,15 |
A1+ |
76 |
4,23 |
eA3 |
77 |
5,79 |
|
8 |
P3 |
24 |
4,75 |
U1 |
63 |
3,51 |
P3 |
66 |
4,96 |
|
9 |
U1 |
23 |
4,55 |
Ep2 |
56 |
3,12 |
HEAD |
59 |
4,43 |
|
10 |
A1+ |
22 |
4,36 |
eA3 |
55 |
3,06 |
ATR |
52 |
3,91 |
|
valency-non-sensitive |
|||||||||
|
|
OTC |
TVP |
LLV |
||||||
|
|
roles |
absolute |
% |
roles |
absolute |
% |
roles |
absolute |
% |
|
1 |
eA |
102 |
20,20 |
eA |
340 |
18,94 |
eA |
304 |
22,84 |
|
2 |
P |
67 |
13,27 |
P |
228 |
12,70 |
P |
207 |
15,55 |
|
3 |
LCT |
62 |
12,28 |
LCT |
180 |
10,03 |
LCT |
173 |
13,00 |
|
4 |
A |
42 |
8,32 |
U |
126 |
7,02 |
R |
124 |
9,32 |
|
5 |
R |
40 |
7,92 |
A |
106 |
5,91 |
CONTdir |
77 |
5,79 |
|
6 |
U |
39 |
7,72 |
R |
106 |
5,91 |
A |
63 |
4,73 |
|
7 |
CONTdir |
31 |
6,14 |
CONTdir |
103 |
5,74 |
EXST |
61 |
4,58 |
|
8 |
Ep |
13 |
2,57 |
EXST |
84 |
4,68 |
HEAD |
59 |
4,43 |
|
9 |
CONTind |
12 |
2,38 |
Ep |
57 |
3,18 |
ATR |
52 |
3,91 |
|
10 |
AFCp |
11 |
2,18 |
AFCp |
54 |
3,01 |
U |
47 |
3,53 |
other figures
Realisation of arguments
Sensitivity of roles for deletion or omission
Congruence patterns between antecedents and anaphoric elements
Reference relations for zero-anaphora (distance-sentitive)
top
Sensitivity of roles for deletion or omission
Fig. 3 gives an overview, which roles are most sensitive to non-realisation. These are clearly the most salient roles, above all those related to humanity, that is semantic agents [+ctr] (A, eA), recipients (R), and ceptors [–ctr] (receptors and perceptors, Ep2). The most prototypical agent (eA2) of a prototypical transitive transformative [+ctr] action is realised only in about 25 to 36% of all instances, in the case of higher valency (eA2+, eA3), the percentage is even lower. Self-controlled movers and similar [+ctr] non-ergative arguments (A1+, A2) are also likely to be deleted. recipients, and ceptors are treated somewhat different in the three texts.
Patients are much less likely to be
non-realised. However, whenever a chain of events
concerns one and the same patient, it has to be
obligatorily deleted in all clauses following ist
explicit mentioning. This yields a fairly high
number of symmetric P < P relations (deleted Ps
following a P-antecedent). Most arguments are
obligatory arguments, only the locational
arguments (LCT, SRC)
and the addressee (R) are frequently omissible. Fig. 2 also shows
that the more salient arguments occur with a
higher frequency than less salient arguments,
particularly if one disregards the valency
distinctions: patients and recipients are
more frequent than subjects of low transitivity.
The high frequency of location arguments is
noteworthy. For all roles and abbreviations see
our definition
of arguments.
|
peripheral
non-subject roles |
|||||||||||||||
|
document |
OTC |
TVP |
LLV |
||||||||||||
|
realisation |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
|
ATR |
1 |
1 |
100,00 |
0 |
– |
48 |
48 |
100,00 |
0 |
– |
52* |
52 |
100,00 |
0 |
– |
|
RST |
0 |
– |
– |
– |
– |
13 |
13 |
100,00 |
0 |
– |
7 |
6 |
85,71 |
1 |
– |
|
PST |
0 |
– |
– |
– |
– |
14 |
11 |
78,57 |
2 |
1 |
4 |
4 |
100,00 |
0 |
– |
|
bArg |
6 |
4 |
66,67 |
2 |
– |
26 |
25 |
96,15 |
1 |
– |
3 |
3 |
100,00 |
0 |
– |
|
PARA |
4 |
4 |
100,00 |
0 |
– |
10 |
10 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
AFCp2 |
11 |
10 |
90,01 |
1 |
– |
54 |
38 |
70,37 |
16 |
– |
22 |
21 |
95,45 |
1 |
– |
|
AFCe2 |
0 |
– |
– |
– |
– |
10 |
6 |
60,00 |
4 |
– |
0 |
– |
– |
– |
– |
|
PATH |
5 |
3 |
60,00 |
2 |
– |
1 |
1 |
100,00 |
0 |
– |
1 |
1 |
100,00 |
0 |
– |
|
CONTdir |
31 |
26 |
83,87 |
4 |
1 |
103 |
96 |
93,20 |
7 |
– |
83 |
65 |
78,31 |
18 |
– |
|
CONTind |
12 |
9 |
75,00 |
3 |
– |
12 |
12 |
100,00 |
0 |
– |
2 |
2 |
100,00 |
0 |
– |
|
CTC |
8 |
7 |
87,50 |
1 |
– |
12 |
11 |
91,67 |
1 |
– |
1 |
0 |
0,00 |
1 |
– |
|
INSTR |
6 |
5 |
83,33 |
1 |
– |
20 |
18 |
90,00 |
2 |
– |
1 |
1 |
100,0 |
0 |
– |
|
SRC |
2 |
2 |
100,00 |
0 |
0 |
20 |
17 |
85,00 |
0 |
3 |
16 |
11 |
68,75 |
0 |
5 |
|
CREL |
0 |
– |
– |
– |
– |
6 |
6 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
demA |
6 |
6 |
100,00 |
0 |
0 |
2 |
2 |
100,0 |
0 |
– |
0 |
– |
– |
– |
– |
|
LCT |
63 |
51 |
80,95 |
3 |
9 |
180 |
119 |
66,11 |
11 |
50 |
173 |
87 |
50,29 |
15 |
71 |
|
peripheral
subject roles |
|||||||||||||||
|
document |
OTC |
TVP |
LLV |
||||||||||||
|
realisation |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
|
HEAD |
1 |
1 |
100,00 |
0 |
– |
48 |
27 |
56,25 |
21 |
– |
59 |
15 |
25,42 |
44* |
– |
|
EXST1 |
0 |
– |
– |
– |
– |
3 |
3 |
100,00 |
0 |
– |
11 |
11 |
100,00 |
0 |
– |
|
EXST1+ |
3 |
3 |
100,00 |
0 |
– |
40 |
34 |
85,00 |
6 |
– |
50 |
40 |
80,00 |
10 |
– |
|
primary
non-subject roles |
|||||||||||||||
|
document |
OTC |
TVP |
LLV |
||||||||||||
|
realisation |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
|
TAR |
7 |
4 |
57,14 |
3 |
– |
18 |
9 |
50,00 |
8 |
1 |
27 |
23 |
85,19 |
4 |
– |
|
R |
40 |
7 |
17,50 |
8 |
25 |
106 |
25 |
23,58 |
15 |
66 |
124 |
61 |
49,19 |
19 |
44 |
|
P2 |
35 |
27 |
77,14 |
8 |
– |
161 |
129 |
80,12 |
32 |
– |
94 |
88 |
93,62 |
6 |
– |
|
P2+ |
7 |
4 |
57,14 |
3 |
– |
24 |
17 |
70,83 |
7 |
– |
47 |
27 |
57,45 |
20 |
– |
|
P3 |
24 |
23 |
95,83 |
1 |
– |
39 |
25 |
64,10 |
14 |
– |
66 |
57 |
86,36 |
9 |
– |
|
P3+ |
0 |
– |
– |
– |
– |
3 |
1 |
33,33 |
2 |
– |
0 |
– |
– |
– |
– |
|
P4 |
1 |
1 |
100,00 |
0 |
– |
1 |
0 |
0,00 |
1 |
– |
0 |
– |
– |
– |
– |
|
primary
subject roles [–ctr] |
|||||||||||||||
|
document |
OTC |
TVP |
LLV |
||||||||||||
|
realisation |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
|
EXST2 |
6 |
6 |
100,00 |
0 |
– |
37 |
37 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
EXST2+ |
0 |
– |
– |
– |
– |
3 |
2 |
66,67 |
1 |
– |
0 |
– |
– |
– |
– |
|
EXST3 |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
U1 |
23 |
18 |
78,26 |
5 |
– |
63 |
44 |
69,84 |
19 |
– |
20 |
17 |
85,00 |
3 |
– |
|
U1+ |
3 |
0 |
0,00 |
3 |
– |
9 |
6 |
66,67 |
3 |
– |
7 |
7 |
100,00 |
0 |
– |
|
U2 |
13 |
7 |
53,85 |
6 |
– |
54 |
23 |
42,59 |
29 |
2 |
18 |
11 |
61,11 |
7 |
– |
|
U3 |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
2 |
1 |
50,00 |
1 |
– |
|
Ee2 |
0 |
– |
– |
– |
– |
10 |
6 |
60,00 |
4 |
– |
0 |
– |
– |
– |
– |
|
Eg2 |
0 |
– |
– |
– |
– |
5 |
5 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
Ee3 |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
|
Ep2 |
14 |
1 |
7,14 |
13 |
– |
57 |
19 |
33,33 |
38 |
– |
24 |
15 |
62,50 |
9 |
– |
|
Ep2+ |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
POSS |
6 |
2 |
33,33 |
4 |
– |
36 |
20 |
55,56 |
16 |
– |
– |
– |
– |
– |
– |
|
CU1 |
0 |
– |
– |
– |
– |
10 |
8 |
80,00 |
2 |
– |
0 |
– |
– |
– |
– |
|
CU1+ |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
CU2 |
0 |
– |
– |
– |
– |
3 |
3 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
CEXST1+ |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
CA1+ |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
CeA2 |
0 |
– |
– |
– |
– |
1 |
0 |
0,00 |
1 |
– |
0 |
– |
– |
– |
– |
|
ME1 |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
|
ME1+ |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
|
ME2 |
2 |
0 |
0,00 |
2 |
– |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
|
eME2 |
1 |
0 |
0,00 |
1 |
– |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
|
E₀ |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
13 |
12 |
92,31 |
1 |
– |
|
primary
subject roles [+ctr] |
|||||||||||||||
|
document |
OTC |
TVP |
LLV |
||||||||||||
|
realisation |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
|
A1 |
2 |
1 |
50,00 |
1 |
– |
2 |
0 |
0,00 |
2 |
– |
1 |
1 |
100,00 |
0 |
– |
|
A1+ |
22 |
5 |
22,73 |
17 |
– |
76 |
25 |
32,89 |
51 |
– |
51 |
25 |
49,02 |
26 |
– |
|
A2 |
18 |
7 |
38,89 |
11 |
– |
27 |
6 |
22,22 |
21 |
– |
9 |
6 |
66,67 |
3 |
– |
|
A2+ |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
0 |
– |
– |
– |
– |
|
A3 |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
2 |
1 |
50,00 |
1 |
– |
|
A2/eA2rfl |
0 |
– |
– |
– |
– |
2 |
2 |
100,00 |
0 |
– |
3 |
0 |
0,00 |
3 |
– |
|
eA1 |
0 |
– |
– |
– |
– |
2 |
0 |
0,00 |
2 |
– |
10 |
0 |
0,00 |
10 |
– |
|
eA1rcp |
0 |
– |
– |
– |
– |
0 |
– |
– |
– |
– |
1 |
1 |
100,00 |
0 |
– |
|
eA2 |
44 |
11 |
25,00 |
33 |
– |
184 |
48 |
26,09 |
136 |
– |
137 |
49 |
35,77 |
88 |
– |
|
eA2+ |
27 |
3 |
11,11 |
24 |
– |
108 |
21 |
19,44 |
87 |
– |
93 |
17 |
18,28 |
76 |
– |
|
eA3 |
27 |
6 |
22,22 |
21 |
– |
56 |
7 |
12,50 |
49 |
– |
77 |
14 |
18,18 |
63 |
– |
|
eA3+ |
1 |
0 |
0,00 |
1 |
– |
3 |
0 |
0,00 |
3 |
– |
0 |
– |
– |
– |
– |
|
eA4 |
6 |
0 |
0,00 |
6 |
– |
1 |
0 |
0,00 |
1 |
– |
0 |
– |
– |
– |
– |
|
CIN |
0 |
– |
– |
– |
– |
18 |
4 |
22,22 |
14 |
– |
0 |
– |
– |
– |
– |
|
the
most salient and/or frequent roles –
disregarding valency |
|||||||||||||||
|
document |
OTC |
TVP |
LLV |
||||||||||||
|
realisation |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
exp. |
real. |
% real. |
del. |
om. |
|
TAR |
7 |
4 |
57,14 |
3 |
– |
18 |
9 |
50,00 |
8 |
1 |
27 |
23 |
85,19 |
4 |
– |
|
U (1-2) |
39 |
25 |
64,10 |
14 |
– |
125 |
73 |
58,40 |
51 |
2 |
47 |
36 |
76,60 |
11 |
– |
|
A (1-2+) |
42 |
13 |
30,95 |
29 |
– |
106 |
32 |
30,19 |
74 |
– |
63 |
33 |
52,38 |
30 |
– |
|
R |
40 |
7 |
17,50 |
8 |
25 |
106 |
25 |
23,58 |
15 |
66 |
124 |
61 |
49,19 |
19 |
44 |
|
LCT |
60 |
48 |
80,00 |
3 |
9 |
180 |
119 |
66,11 |
11 |
50 |
173 |
87 |
50,29 |
15 |
71 |
|
P (2-4) |
67 |
55 |
82,09 |
12 |
– |
228 |
172 |
75,44 |
56 |
– |
207 |
172 |
83,09 |
35 |
– |
|
eA (2-4) |
105 |
20 |
19,05 |
85 |
– |
354 |
76 |
21,47 |
278 |
– |
307 |
80 |
26,06 |
227 |
– |
For all roles and abbreviations see our definition of arguments.
other figures
Realisation of arguments
Distribution of arguments (the ten most frequent roles)
Congruence patterns between antecedents and anaphoric elements
Reference relations for zero-anaphora (distance-sentitive)
top
Congruence patterns between anaphora and their antecedents
We have evaluated the annotations for the relation between empty arguments and their antecedents with respect to their roles. While we believe that valency distinctions play a crucial role and should not be neglected (or not in all cases: they seem to be more important for less prototypical ‘transitive’ roles than for those of the upper section of the transitive hierarchy), it is also clear that the combinatory potential is growing exponentially, and in the case of the TVP (although not in the case of the LLV) we got, in fact too much ‘noise’, that is too many combinations with only single or low numbers of occurrences. We, therefore run the evaluation a second time, taking out all valency distinctions, except that between eA1 (single argument in the ergative) and all other ergative arguments (eA2, eA2+. etc.), see also the last section of Fig. 3 above. We kept all other semantically ([±control], event-type) or morphologically (case marking) relevant distinctions.
Since practically (almost) all possible
combinations concerning the roles of an anaphoric element and its antecedent are attested, only weak
preferences (around 75%) for congruence with respect
to either control or subjecthood can be observed. Control or subjecthood congruence means that either both
antecedent and anaphora display the features or both
lack them. The latter, i.e. congruence with respect
to [–control] and [–subjecthood] is clearly the
preferred pattern for pronominal anaphora. But the
opposite is not true for zero-anaphora, even though
both types of anaphora are functionally distributed.
We have not yet annotated enough data to draw robust conclusions, but it seems that the Old Tibetan text prefers [±control]-congruence over [±subjecthood]-congruence, while the Classical Tibetan text shows the opposite preference. In both cases, congruence for [±control] means that arguments lacking control, e.g. Ps and Us (and possibly Ep.s) are much more likely to be paired than (subject) arguments displaying control (As and eAs). This preference appears to be even higher in the classical text. The chance that subjects are paired is in both cases only slightly higher than 50%.
Interestingly enough, the preferences for subjecthood and control congruence as well as a combination of both are stronger in the Ladakhi text. Even more striking is the preference for subjecthood among the zero-anaphora, going along with a non-preference for negative or positive control values. This difference may reflect the differences between written and oral literature as much as an ongoing language change.|
all anaphora |
||||||
|
|
OTC |
TVP |
LLV |
|||
|
all
instances |
215 |
% |
615 |
% |
637 |
% |
|
[±subjecthood] congruence |
106 |
49,30 |
464 |
75,45 |
513 |
80,53 |
|
[+subjecthood] |
102 |
47,44 |
275 |
44,72 |
347 |
54,47 |
|
[±control] congruence |
168 |
78,14 |
427 |
69,43 |
529 |
83,05 |
|
[+control] (& [+subjecthood])* |
72 |
33,49 |
129 |
20,98 |
227 |
35,64 |
|
[±subj] & [±ctr] congruence |
87 |
40,47 |
368 |
59,84 |
455 |
71,43 |
|
role congruence valency sensitive |
37 |
17,21 |
91 |
14,80 |
149 |
23,39 |
|
role congruence valency non-sensitive |
53 |
24,65 |
129 |
20,98 |
256 |
40,19 |
|
case congruence |
104 |
48,37 |
216 |
35,12 |
331 |
51,96 |
|
zero-anaphora |
||||||
|
|
OTC |
TVP |
LLV |
|||
|
all instances |
171 |
% |
444 |
% |
398 |
% |
|
[±subjecthood] congruence |
102 |
59,65 |
331 |
74,55 |
346 |
86,93 |
|
[+subjecthood] |
102 |
59,65 |
258 |
58,11 |
288 |
72,36 |
|
[±control] congruence |
133 |
77,78 |
278 |
62,61 |
333 |
83,67 |
|
[+control] (& [+subjecthood])* |
72 |
42,11 |
126 |
28,38 |
213 |
53,52 |
|
[±subj] & [±ctr] congruence |
83 |
48,54 |
241 |
54,28 |
306 |
76,88 |
|
role congruence valency sensitive |
32 |
18,71 |
74 |
16,67 |
77 |
19,35 |
|
role congruence valency non-sensitive |
48 |
28,07 |
112 |
25,23 |
174 |
43,72 |
|
case congruence |
97 |
56,73 |
187 |
42,12 |
205 |
51,51 |
|
pronominal
anaphora |
||||||
|
|
OTC |
TVP |
LLV |
|||
|
all instances |
44 |
% |
171 |
% |
239 |
% |
|
[±subjecthood] congruence |
4 |
9,09 |
133 |
77,78 |
167 |
69,87 |
|
[+subjecthood] |
0 |
0,00 |
17 |
9,94 |
59 |
24,69 |
|
[±control] congruence |
35 |
79,55 |
149 |
87,13 |
196 |
82,01 |
|
[+control] (& [+subjecthood])* |
0 |
0,00 |
3 |
1,75 |
14 |
5,86 |
|
[±subj] & [±ctr] congruence |
4 |
9,09 |
127 |
74,27 |
149 |
62,34 |
|
role congruence valency sensitive |
5 |
11,36 |
17 |
9,94 |
72 |
30,13 |
|
role congruence valency non-sensitive |
5 |
11,36 |
17 |
9,94 |
82 |
34,31 |
|
case congruence |
7 |
15,91 |
29 |
16,96 |
126 |
52,72 |
other figures
Realisation of arguments
Distribution of arguments (the ten most frequent roles)
Sensitivity of roles for deletion or omission
Reference relations for zero-anaphora (distance-sentitive)
top
Reference relations for zero-anaphora (distance-sensitive)
While there is no significant general preference for congruence patterns or particular roles, some combinations do occur more frequently than others, among them clearly agent-centred roles [+ctr]. The most common among these is the congruent combination of two ergative agents, or combinations between ergative and absolutive agents. The overall frequencies depend, however, on the number of clauses that intervene. While it is typically actor related combinations that hold over long distances, one may find other roles more frequently over short distances.
This becomes most strikingly apparent in the case of the LLV, where congruent patient-patient relations turn out to be clearly the most frequent relations over a distance of one clause only. Only if all agent-agent relations are summed up, whether they show case congruence or not, they outnumber the patient-patient relations.
This is, in a way, quite surprising, since patients occur by about one third less frequently than ergative agents (as ergative agents also occur with patient-less directional activity verbs), not to speak of all agents together, and patients are also much less frequently omitted (see fig. 3 above). This latter outcome, of course, reflects the simple fact that patients are not commonly acted upon in a multiple way. From this it follows that if such multiple acting upon identical patient does occur, patients have to be obligatorily deleted in all following sequences, except, perhaps, if due to growing distance, the reference becomes ambiguous. (Yet all beginners in Tibetan studies suffer considerably because ambiguities are more often than not – not resolved.) Quite naturally, identical patients might be part of a clause immediately following their first mention (an ideal szenario would be the preparation of something for further action, e.g. peeling, washing, or cutting a fruit for consumtion). Agents, by contrast, may be deleted over comparatively long distances, and long distances, again allow more possibilities of combinations. For these reasons the likelyhood of agent-agent relations decreases somewhat over short distances.
The LLV also shows an extreme case, where agent-agent relations were outnumbered by a peripheral relation over a distance of two clauses: the deleted head of a predication verb referring back to a PATIENT. The high number of head-arguments in this text and their deletion is not very significant, since it is the result of endless repetitions in songs or enumerations of treasuries.
That the high frequency of patient-patient relations over short distances is not a genre-relevant artefact in the LLV, is also shown by the results of the two other texts, even if the frequencies are clearly lower than those of congruent (ergative) agent-relations.
In order to make the results more comparable, and to make the more significant facts apparent, we have reduced all valency distinctions, with the exception of eA1-arguments, that is, ergative marked sole arguments. The following figures, representing reference relations for distances of one to five clauses, have been further cleared off all marginal non-congruent role-relations (represented only in light grey). We will, however, indicate congruent relations of peripheral roles. This must be enough to show that, in principle, every combination is possible.
Key to figs. 5a - 5c:
The embedded circles represent the clause distances, the outer-most circle a distance of 1, the inner-most a distance of 5. The percentages indicated are based on the total number of reference relations over a given distance.
Fig. 5 Synopsis
|
OTC (Fig.
5a) |
TVP (Fig.
5b) |
LLV (Fig.
5c) |
|
|
|
|
Fig. 5a: Reference relations (zero-anaphora) in OTC
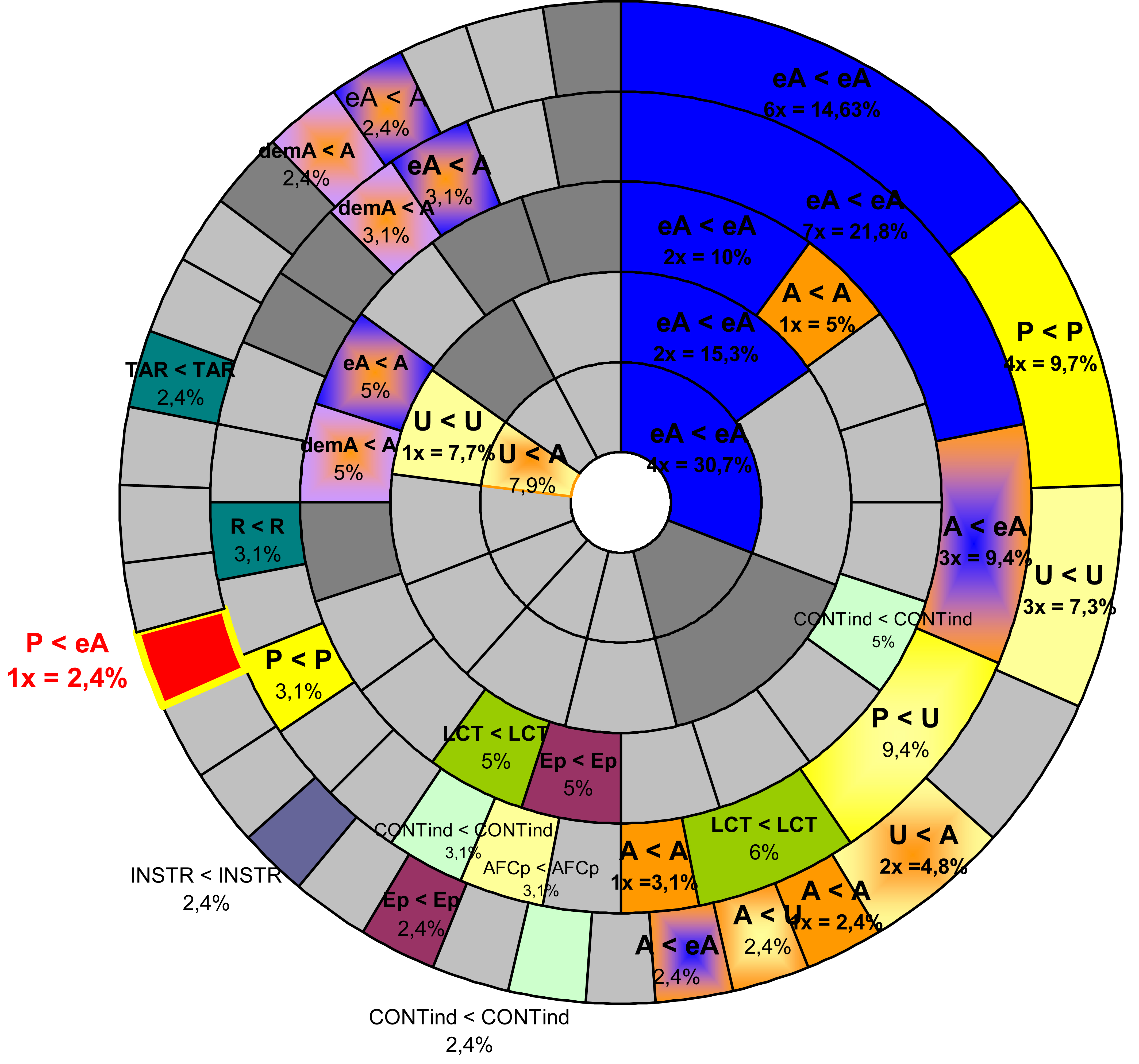
Fig. 5b: Reference relations (zero-anaphora) in TVP
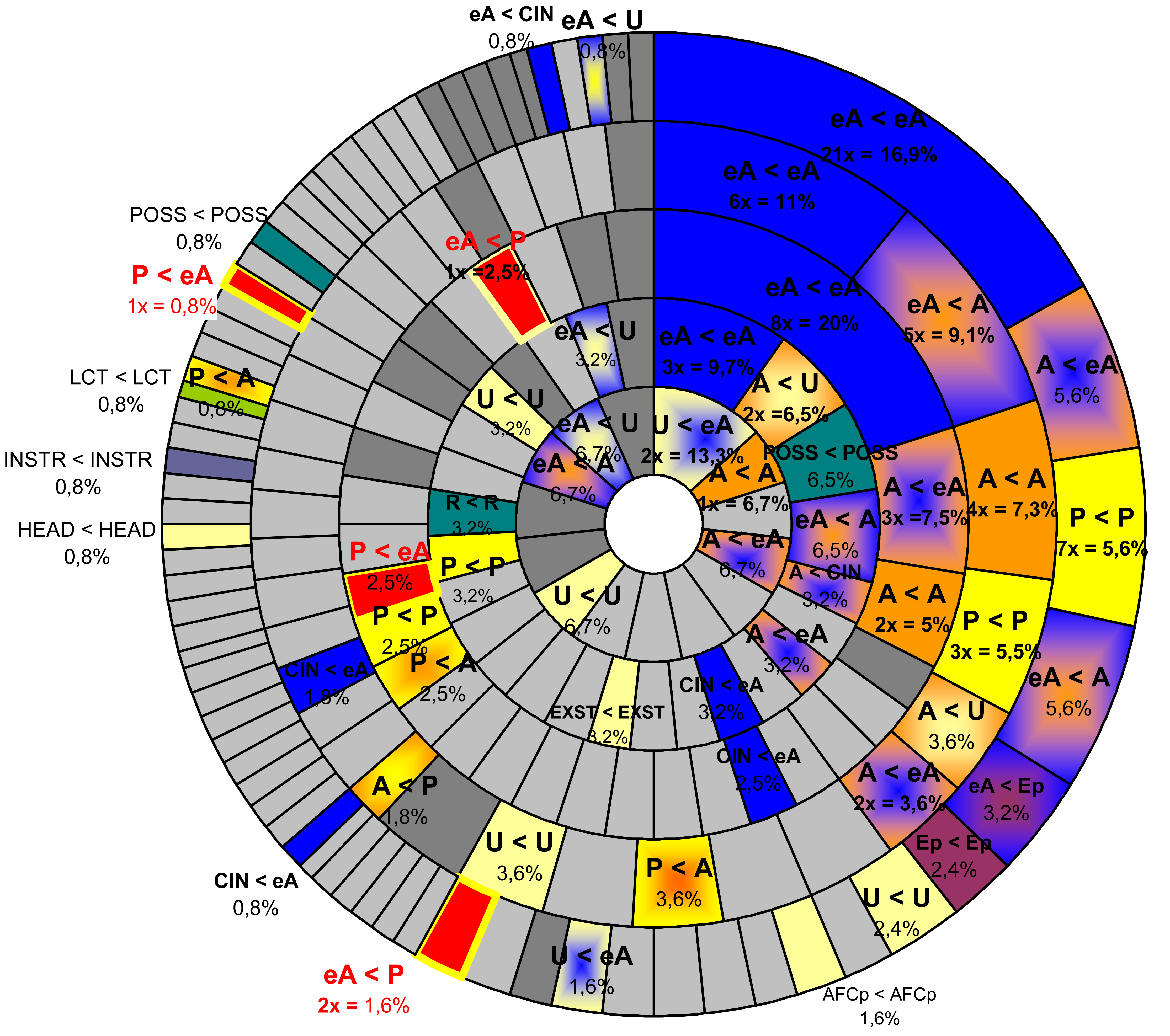
Fig. 5a: Reference relations (zero-anaphora) in LLV
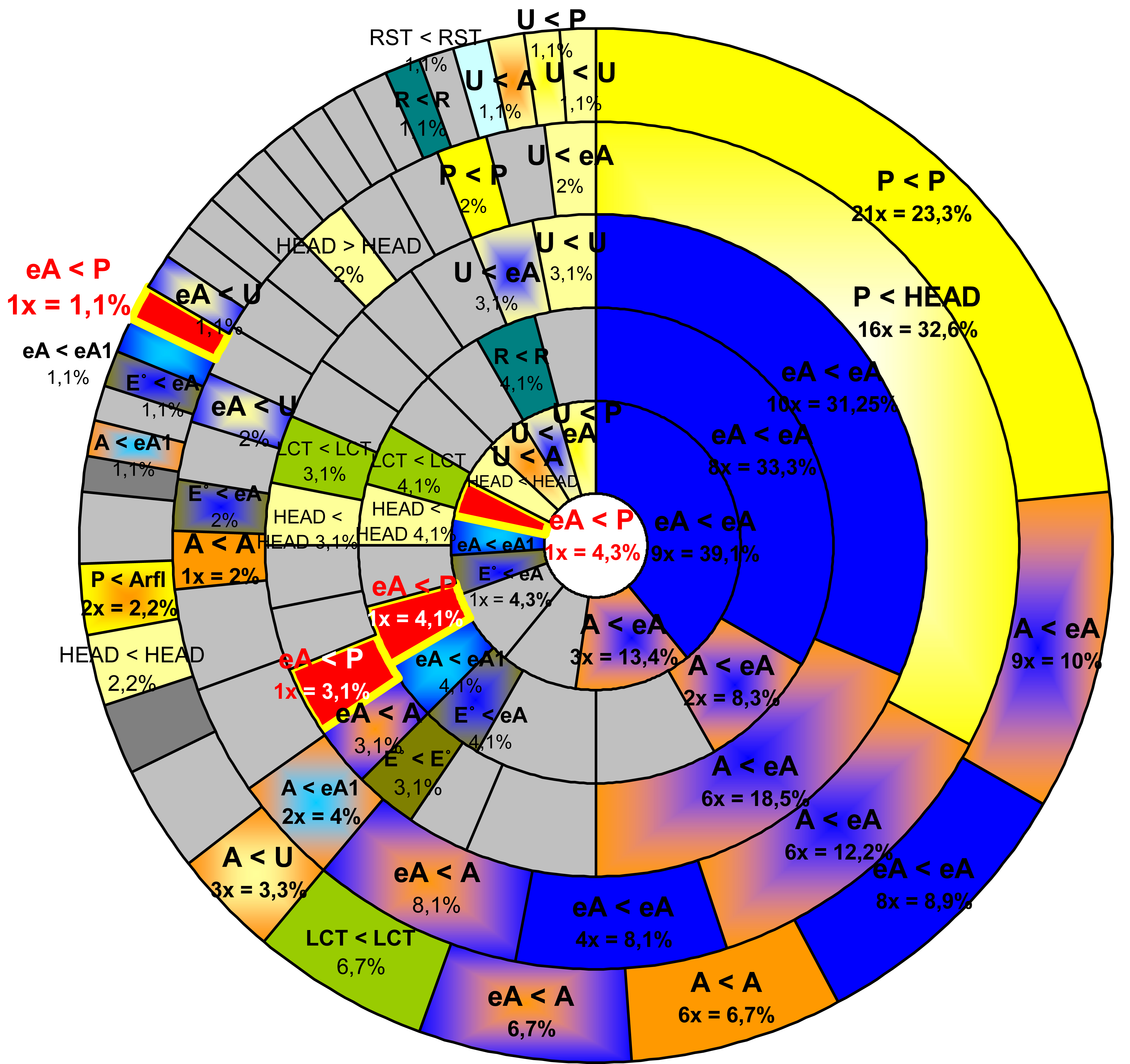
Cross clausal cross references had been predicted by Cooreman, A., Fox, B. and Givón, Talmy (1984) as falling into three types:
Neutral reference (case and subjecthood are congruent): eA < eA; P < P
Accusative reference (congruence of subjecthood): eA < S; S < eA
Ergative reference (congruence of case, Abs): P < S; S < P
What was not predicted, is the total non-congruent reference (neither case nor subjecthood): P < eA; eA < P.
Ladakhi and Tibetan do not show any syntactical restriction (or pivot) for deletion of arguments under clause chaining, although one can see a certain preference for congruence of the feature [±control] and neutral and “accusative” references can be observed.
Cooreman, A., Fox, B. and Givón, Talmy. 1984. „The discourse definition of ergativity“, Studies in Language 8: 1–34
Realisation of arguments
Distribution of arguments (the ten most frequent roles)
Sensitivity of roles for deletion or omission
Congruence patterns between antecedents and anaphoric elements
top
Layout: Christoph Singer. Responsible for the content: B. Zeisler. Last modified: 08.04.2009